Open Access
Research Article
Max Screen >>
ISSN: 2348-9804
Copyright: © 2021 Ariff S. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Related article at Pubmed, Google Scholar
Most forensic investigations are done based on the forensic expert’s level of expertise. This has led to different methods and opinion in coming up with the denominator estimation for a likelihood ratio. Likelihood ratio (LR) though used to measure the strength of evidence in a forensic environment, a number of issues arise when trying to estimate it. Same data set has been applied to existing method in estimating denominator and they have all come up with significantly varying results.
This paper estimate likelihood ratio denominator in the presence of no nuisance; handwriting profiles for each writer was modeled using the back-propagation neural network (BPNN) from handwriting gathered over a period of time. One-on-one exhaustive mapping among every individual believed to be a suspect in the pool of database generated the denominator for our proposition.
Our results supported Hp (LR>1.00) with 97.6% and 90.42% for best case and worst case respectively and was against Hp (LR1.00) with 2.4% and 8.98% for best case and worst case respectively with an inconclusive rate of 0% for both cases and a low disagreement rate while stating the upper and lower confidence interval for all cases.
In this paper, we presented an exhaustive mapping model for modified LR which differs compared to existing methods in approach to generating a denominator database. Our results showed that the writing pattern of an individual when learnt over a period of time, with one-on-one exhaustively mapping to estimate the denominator will not only lead to a likelihood ratio with no nuisance parameter involved but also a likelihood ratio with no inconclusiveness and a low rate of disagreement.
Keywords:ANN; Denominator; Forensic Disagreement; Forensic Inconclusiveness; Forensic Investigation; Numerator; Nuisance Parameters
A lot of crucial information can be gotten from documents related to a criminal or civil case. For example, there may be an alteration in will; we might have a suicidal note by a suspect who is trying to erase traces amongst other questioned document.
Forensic document examiners are then left with questions of document authenticity. To determine whether a document is genuine, an examiner may attempt to confirm who created the document amongst other things.
Handwriting is a key element of document examination. Forensic examination and comparison of handwriting, which includes hand printing and signatures. The concept of handwriting was described in [1,2].
Questioned document analysis is the process where various scientific techniques are applied by a forensic expert for examining such documents. Questioned document analysis helps us to reveal many hidden evidences about the committed crime. Nowadays forensics and criminal analysis are becoming extremely data intensive. In some situations, forensic experts need to deal with a lot of paper documents from heterogeneous sources.
Principles and identification of handwriting were stated in [3-6,7]. For the majority of the 20th century, the forensic identification of handwriting has had great recognition and acceptance as forensic evidence. However, in recent times, there have been a number of questions raised regarding the scientific validity and court presentation of forensic handwriting identification [8-11].
Forensic currently uses a uniform and logical inference model for evaluating and reporting forensic evidence [12]. It uses a likelihood ratio (LR) approach based on the Bayes inference model (Theorem of conditional probabilities). In a criminal case, there is handwriting from a crime scene, e.g., documents recovered at the scene of crime as well as handwriting from the suspect. The responsibility of a forensic scientist is to give a Likelihood Ratio (LR) instead of a decision to the court [13]. Then, it is the responsibility of the judge or the jury to make a decision which involves other sources of information about the case at hand. Use of a LR to report the output of a biometric comparison is gradually becoming a standard way of evidence evaluation from score-based biometric systems.
A LR is a more objective and useful output in forensic evaluation than simply a score [14,16]. A general description of the LR framework for evidence evaluation from biometric systems can be found in [17]. It is applied to several biometric modalities including forensic voice [18], speaker [17,19,20] and fingerprint comparison [21]. Preliminary results of evidence evaluation using handwriting recognition systems as a case study are presented in [22-24]. A LR is the probability of the score given the prosecution hypothesis is true divided by the probability of the score given the defense hypothesis is true:
The likelihood ratio paradigm has been studied as a means for quantifying the strength of evidence for a variety of forensic evidence types.
One interpretation of a likelihood ratio based on Bayes’ theorem is as the multiplicative factor by which the ratio of the probabilities of two propositions changes with observation of the evidence. For example, suppose the trier of fact can quantify beliefs about guilt prior to consideration of the new information, i.e., the evidence. A likelihood ratio for each piece of evidence can be used to update prior (before viewing evidence) belief to posterior (after viewing evidence) belief given the new evidence according to the following formula:
Posterior probability ratio = likelihood ratio * prior probability ratio
Formally, the trier of fact could then reach a final decision using the posterior odds in favor of Hp (e.g., the suspect’s guilt) given the evidence. In this paradigm, the trier of fact is responsible for quantifying prior beliefs about Hp and Hd, while the forensic scientist is responsible for providing a summary of the evidence needed to update these beliefs given the evidence. Attempts to date to utilize such an interpretation in court have met with some opposition. Findings in terms of a likelihood ratio from different experts were summarized in [25] while [26] stated the adopting procedures on which a likelihood ratio should be based on and [27] discussed its evaluation criteria.
There are many different methods in literature to compute LR values [23,29-34], feature-based [28,29] and score-based [23,29-31].
This paper proposes a modified likelihood ratio for forensic evaluation in handwriting using the Bayes’ inference model. In the context of the inference of identity of source, the modified Likelihood Ratio is used to evaluate the strength of the evidence for a trace specimen against that of reference.
Likelihood Ratio can be seen as part of the forensic evaluation process [12] used a uniform and logical inference model for evaluating and reporting forensic evidence where they used likelihood ratio (LR) approach based on the Bayes inference model ( i.e. Theorem of conditional probabilities).
It can also be seen as a part of the decision process. Forensic scientists have to conceive new methods and solutions to specific forensic open/research questions. They also have to focus on the development and validation of these new methods conceived and solutions creating new technologies or adapting old or existing technologies for some specific forensic purpose e.g. the development of computer-assisted methods for forensic evidence evaluation. The newly developed LR method is tested in a full Bayes’ inference model, for an extensive range of prior and posterior probabilities related to the propositions, thresholds and decision costs/utilities. Such tests simulate the functionality of the method for the whole range of conditions and the results allow establishing the limits in which the method provides a reliable strength of evidence to the trier of fact. Then the evaluation of the developed LR has to be done. The most relevant and most suitable alternative propositions are to be considered when carrying out this task, using the most suitable method to provide the most correct strength of the evidence in form of a LR [25].
In a score-based method, the LR values are calculated from the comparison scores [15,20] which are typically the result of a comparison performed by pattern recognition algorithms. These extract and compare the features of trace (T) and reference (R) specimens. The score (E) results from this comparison are used to compute a likelihood ratio with the LR method (Bayes’ inference model), using a dataset of trace specimens (DB Traces) and a dataset of reference specimens (DB References). Score-based approaches are traditionally used in forensic biometrics and a typical example can be found.
It is often believed that an individual’s writing profile is a latent characteristic that cannot be observed directly, and is not easily modeled because an individual’s writing profile cannot have static characteristics and may change over time [7,23,28,29] adopted ad-hoc method to compute likelihood ratio in the presence of nuisance parameter because their system could not model the writing profile for each writer [7,31,32] used a marginal likelihood ratio when full likelihood ratio wasn’t an option.
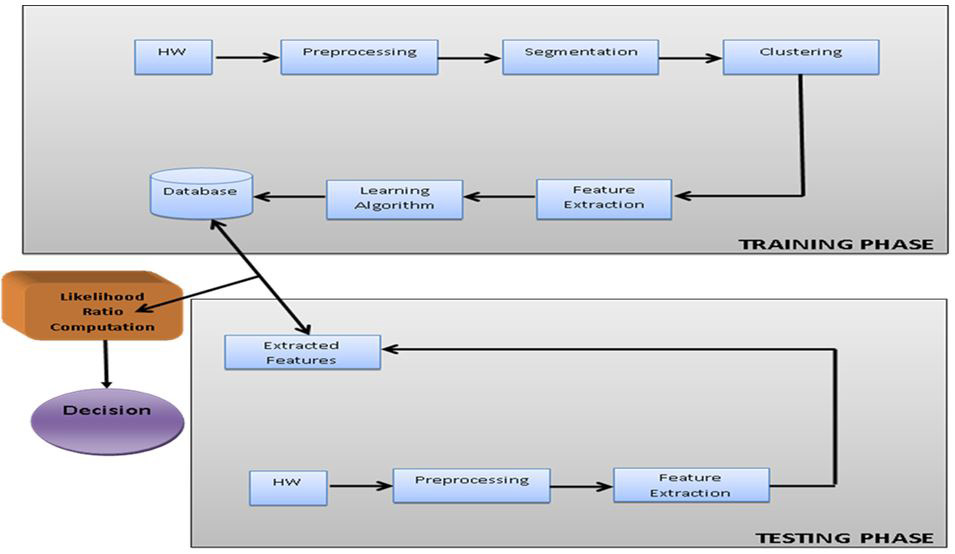
Original, disguised and forged handwritings were gotten from each writer. These writings were scanned and preprocessed. The Sobel edge detection was used to segment these writings into different words. The C-means clustering algorithm was used to cluster these words into individual characters while local binary pattern was used to extract feature vectors from these characters. The extracted feature vectors were fed into the back-propagation neural network BPNN to learn the writing pattern for each individual and they were stored in the database. The same procedures were repeated for the questioned documents and the likelihood ratio was computed based on these patterns as shown in Figure 1 above.
BPNN modeled writing profile for each writer. BPNN is a supervised network with a target, so a target was set for each character in the handwriting. The target will help us know which handwriting is original and disguised.
BPNN processes information the way in which the human brain processes information by gathering their knowledge through detecting the patterns and relationships in data and learn through experience.
One of the most popular NN algorithms is back propagation algorithm, [34] used it with momentum in their work for signature recognition. [33] Claimed that BPNN algorithm could be broken down to four main steps. After choosing the weights of the network randomly, the back propagation algorithm is used to compute the necessary corrections. The algorithm can be decomposed in the following four steps:
i) Feed-forward computation ii) Back propagation to the output layer iii) Back propagation to the hidden layer iv) Weight updates
The algorithm is stopped when the value of the error function has become sufficiently small. This is very rough and basic formula for BP algorithm. There are some variations proposed by other scientist but Rojas definition seem to be quite accurate and easy to follow.
Each character variable has a weight Wi which shows its contribution in the training process. The feature information extracted from student’s handwritten via local binary pattern (LBP) was fed into NN via input layer and participation of each category of character variables is determined at a hidden layer of the network using:
The LBP feature vector of every alphanumeric character of each writer’s handwriting, in its simplest form was created in the following manner:
1. Divide the examined window into cells (e.g. 16x16 pixels for each cell). 2. For each pixel in a cell, compare the pixel to each of its 8 neighbors (on its left-top, left-middle, left-bottom, right-top, and so on). 3. Follow the pixels along a circle, i.e. clockwise or counterclockwise. 4. In the above step, the neighbors considered can be changed by varying the radius of the circle around the pixel, R and the quantization of the angular space S. 5. Where the center pixel’s value is greater than the neighbor’s value, write “0”. Otherwise, write “1”. This gives an 8-digit binary number (which is usually converted to decimal for convenience). 6. Compute the histogram, over the cell, of the frequency of each “number” occurring (i.e., each combination of which pixels are smaller and which are greater than the center). This histogram can be seen as a 256-dimensional feature vector. 7. Optionally normalize the histogram. 8. Concatenate (normalized) histograms of all cells. This gives a feature vector for the entire window.
Where gc and gp denote the intensity of the current and neighboring pixel, respectively. P is the number of neighboring pixels chosen at a radius R. In this study P=8-neighbor.
The feature vector can now then be processed using back propagation neural network algorithm to classify each character images.
The feature vectors extracted from each writer’s handwriting via local binary pattern (LBP) was fed into neural network NN through the input layer Each category of character variables participation was determined at a hidden layer of the network and the excitation nett of the s-th hidden unit is given by using:
Nets is ith category of variable, m is count of variables in nets, and ôi is the ith recognition variable with weight (1)
We considered a network with m input sites, n1 and n2 hidden, and k output units. The input sites were the original, disguised and forged handwritings which contains all lower and upper case alphabets with special and numeric characters for all writers producing three weights for 1st and 2nd hidden layers as well as three outputs in order to differentiate these handwritings. The weight between the constant 1 and two hidden unit s is called (1)1,1mnw+ and (2)11,2nnw+and the weight between the constant 1 and the output unit j is denoted by (3)21,knw+. The m-dimensional input vector 0=(01,..., 0m) was extended and transformed to ô=(o1,...,om,1) .
The numerator in handwriting is not really an issue as numerator will always be from the same source as it is all about the questioned document but a number of issues arise when one considers how to go about estimating the denominator for the likelihood ratio. Some of these issues are related to what approach are used in generating the denominator. Three different approaches have been considered using the same dataset but generating different results in the presence of nuisance parameters. These approaches include pairing (1) the item of known source with randomly selected items from a relevant database; (2) the item of unknown source with randomly selected items from a relevant database; (3) two randomly generated items.
The numerator in handwriting is not really an issue as numerator will always be from the same source as it is all about the questioned document but a number of issues arise when one considers how to go about estimating the denominator for the likelihood ratio.
We considered a modification to the likelihood ratio to eliminate the presence of nuisance parameters. Though the numerator still remains about the document in question but when it comes to estimating the denominator, one-on-one exhaustive and inclusive mapping with the writing profile generated for each writer was employed. This we believe will help investigators in the course of their investigation and as well eliminate nuisance parameter (such as crime scene, information given when being interrogated etc.) though the nuisance parameter could be instrumental in getting our suspect but it could be a times misleading [15]. This approach generates the denominator by picking a known source against every other writer in the pool of relevant database. The formula is:
Where P(y/θ) is the conditional probability that the questioned document exist given that the suspect is the originator, y is a variable, θ = Suspect. The denominator will be an m ×n matrix where everybody goes round with every other person in the database of pool of suspected criminals
(E.) = one on one Exhaustive Mapping
Where
E (.) = k E (.) = (yt ∕ θt)(θt) E (.) is a bias function that corroborates the presence or otherwise of a suspect within the crime scene instead of randomizing them. Where t = 1, 2, 3, 4, 5………., m And k = 1, 2, 3, 4, 5………, n
Where m, n is a m * n matrix exhaustive and inclusive because everyone is been picked and we pick without replacement so it’s a balance and square matrix [15] highlighted different mentioned for denominator generation in a LR but all in the presence of nuisance but full LR wasn’t an option.
Under the numerator hypothesis Hp, the source of c and d are the same (e.g. the suspect wrote the questioned document, the document found on the suspect is from the suspect’s domain). Thus c and d are random (independent) draws from the same distribution, Normal distribution so that μa = μb. Therefore
C ~ N (μx, σ2w), D ~ N (μx, σ2w), Noting that the joint density for two independent normal random variables is simply the product of their respective densities, we have f (c,d|Hp) = :c and pHdarise from the same source Hd : c and d arise from different sources Assuming a and b are continuous measurements is defined by
Original and disguised handwriting obtained over a period of six month was gotten from 230 writers for this work. A skilled forgery was done to the original writing of each writer in the database. 690 of original, disguised and forged handwriting samples were collected from the writers and used for this paper.
The estimate obtained from the exhaustive mapping denominator using Kernel Density Estimator was highly variable compared to previous methods used to estimate the denominator. To illustrate for one iteration from the results gotten, values obtained from the first suspect against every other person in the pool of database were estimated likelihood ratio ELR1= 1.5389 ELR2= 9.4649 ELR3 = 1.6004 ELR4= 1.0914 till ELR229= 0.0075 with the overall LR =97.6%. Another iteration i.e. the second person going round with the first suspect and every other suspect in the pool of database obtained ELR1= 1.2556 ELR2= 0.0251 ELR3= 1.0680 ELR4= 1.1203 ELR229=9.0323 with the overall LR= 95.21% for the second person where Hp is true,
This trend continued over so many iterations till every suspect/ person in the pool of database went round with all other suspect in that pool of database. The summary of the results are shown in Table 1. Based on decision rule i.e. Hp will be true if LRkde value > 1, Hp will be false if LRkde value 1 and inconclusive if and only if LRkde value = 1 with the upper and lower bound confidence interval being stated. A disagreement rate as low as 2.4% was observed that is 2.4% of the time our method disagreed with the others as to whether or not the evidence supports Hp. Interval estimate is statistically considered robust over point of estimate; therefore
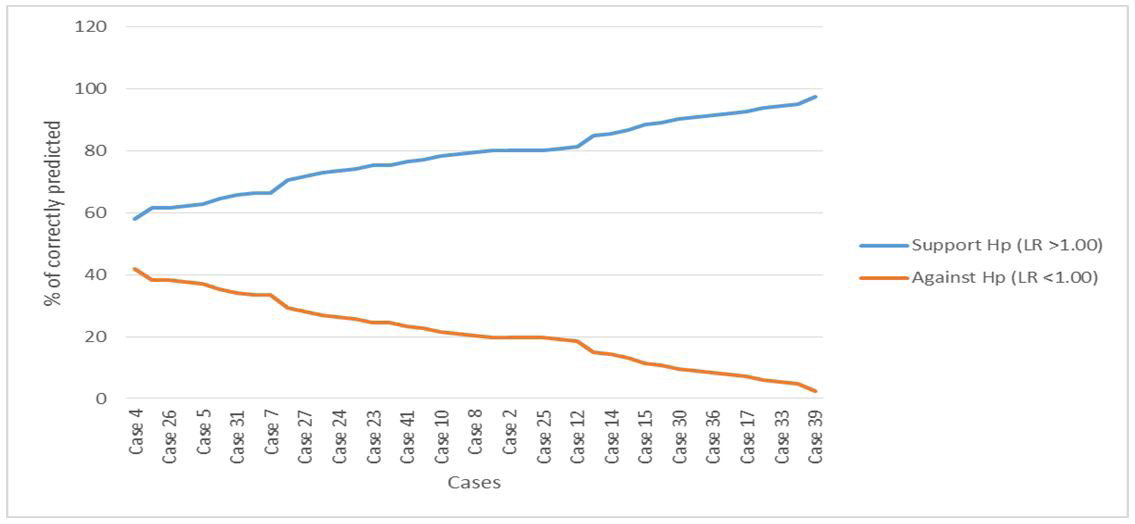
we considered the interval estimate that is estimated likelihood ratio to putting the decision condition into consideration. Both the lower and upper interval must have the same sign; they must either be either positive or both negative. Uniformity in sign indicates an agreement otherwise there is disagreement. There was a low disagreement rate generally and a 0% inconclusiveness indicating that the choice of our denominator proposition dealt with the problem of inconclusiveness and lowers the rate of disagreement as shown in table 1. Our method was compared by the measurement of error rates as described in [33]: RMED≡ the rate of misleading evidence in favor of the defense, i.e., when Hd is true (Against Hp (LR <1.00)). The agreement rates i.e. LR Support Hp (LR >1.00) and disagreement rates i.e. LR against Hp (LR 1.00) are shown in Figure 2. Agreement rate scaled from 60% above while the disagreement rate/rate of misleading evidence was 40% below for our modified likelihood ratio estimates.
Existing literature have had divergent opinions when estimating their denominators for a likelihood ratio which is due to some many factor. Though various forensic examiners performs their examinations based on their own level of expertise and with different parameters. Some literature have reported results based on crime scene while other have used parameters best known to them which they classify as nuisance and led to high rate of inconclusive results. The nuisance parameters though instrumental in their process of investigation but led to these challenges which could not be over looked. Our work came up with a way to estimate the denominator that will produce consistent likelihood ratio estimates in the absence of nuisance parameters with no inconclusive results by developing a one-on-one exhaustive mapping model for the denominator proposition as reported in Table 1 below. The one-on-one exhaustive mapping makes the investigation a m × n matrix which is an inclusive and exhaustive investigation whereby everybody from the pool of relevant database are involved instead of just narrowing the investigation down to crime scene and picking denominator proposition for suspects at random.
An Exhaustive Mapping Model for Modified Likelihood Ratio for Handwriting Recognition in Forensic was illustrated based on writing profile for each writer. The results from Table 1 indicate extremely low disagreement rate and no inconclusive rate. The writing profile being modeling with appropriate choice of denominator proposition led to an improved performance of LR. Though assumptions were made but subjective decisions by the Forensic Examiners were not employed to calculate quantities, rather we employed objective facts to come up with a LR with quantitative measures and analyses.
The primary purpose of this paper is to highlight to the forensic and pattern recognition community at large through empirical study that likelihood ratio can be interpreted from objective fact rather than the subjectivity of the document of the document examiner/analyst. An examiner / analyst need not worry about his/her own (1) similarity (dissimilarity) score as in the case of score-based likelihood ratio (2) the appropriate interpretation of the denominator (3) the distributions for the numerator and denominator as varying any of these based on his/her subjective mind may affect the outcome of the but rather compute based on objective fact.
Some other conclusions that can be drawn from the result presented above is that the performance of the modified LR will not heavily depend on the size and representation of the database as each writer’s profile would have already being stored in the database. The questioned document and template used here are representation of the general population that might be obtained in real case work. As mentioned earlier, our intention is to simply illustrate the feasibility of obtaining an objective LR for handwriting evidence.

![]()

 |
|
Figure 1: Overview of the graphical model employed for this research |
 |
|
Figure 2: Rate of agreement and disagreement for the modified likelihood ratio |
|
Known & Exhuastive |
||||
Case |
Support Hp (LR >1.00) |
Against Hp (LR <1.00) |
LCI (95%) |
UCI (95%) |
Disagreement |
1 |
97.6 |
2.4 |
95.29 |
99.91 |
2.4 |
2 |
95.21 |
4.79 |
91.98 |
98.44 |
4.79 |
3 |
94.61 |
5.39 |
91.20 |
98.02 |
5.39 |
4 |
94.01 |
5.99 |
90.42 |
97.60 |
5.99 |
5 |
92.82 |
7.19 |
88.91 |
96.73 |
7.19 |
6 |
92.22 |
7.78 |
88.17 |
96.27 |
7.78 |
7 |
91.62 |
8.38 |
87.43 |
95.81 |
8.38 |
8 |
91.02 |
8.98 |
86.70 |
95.34 |
8.98 |
9 |
90.42 |
9.58 |
85.97 |
94.87 |
9.58 |
10 |
89.22 |
10.78 |
84.53 |
93.91 |
10.78 |
Table 1: Rates of agreement and disagreement for the LR estimates for our known and one-on-one exhaustive mapping model




































